
How intelligent is a model that memorizes the answers before an exam? That’s the question facing OpenAI after it unveiled o3 in December, and touted its model's impressive benchmarks. At the time, some pundits hailed it as being almost as powerful as AGI, the level at which artificial intelligence is capable of achieving the same performance as a human on any task required by the user.
But money changes everything—even math tests, apparently.
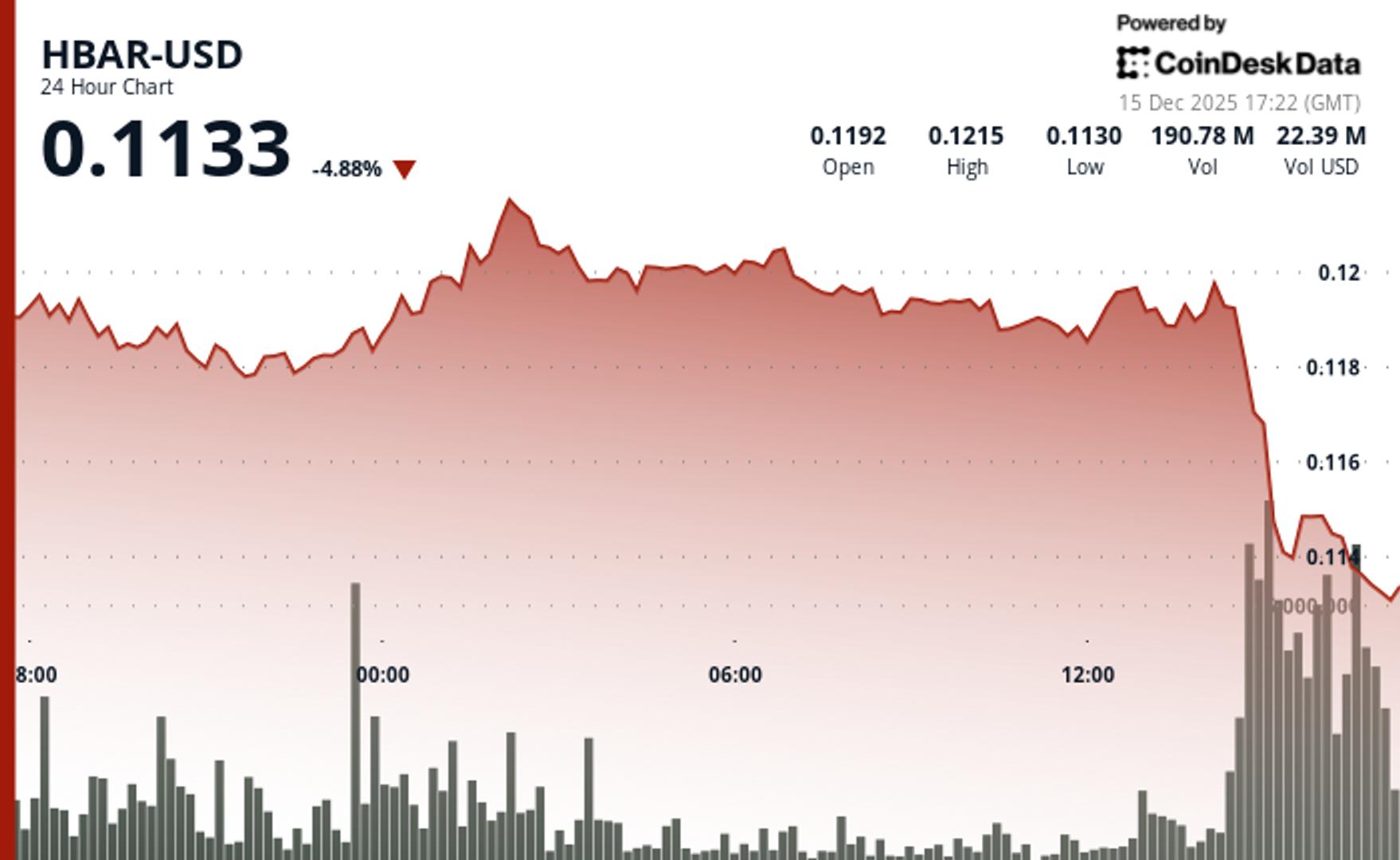
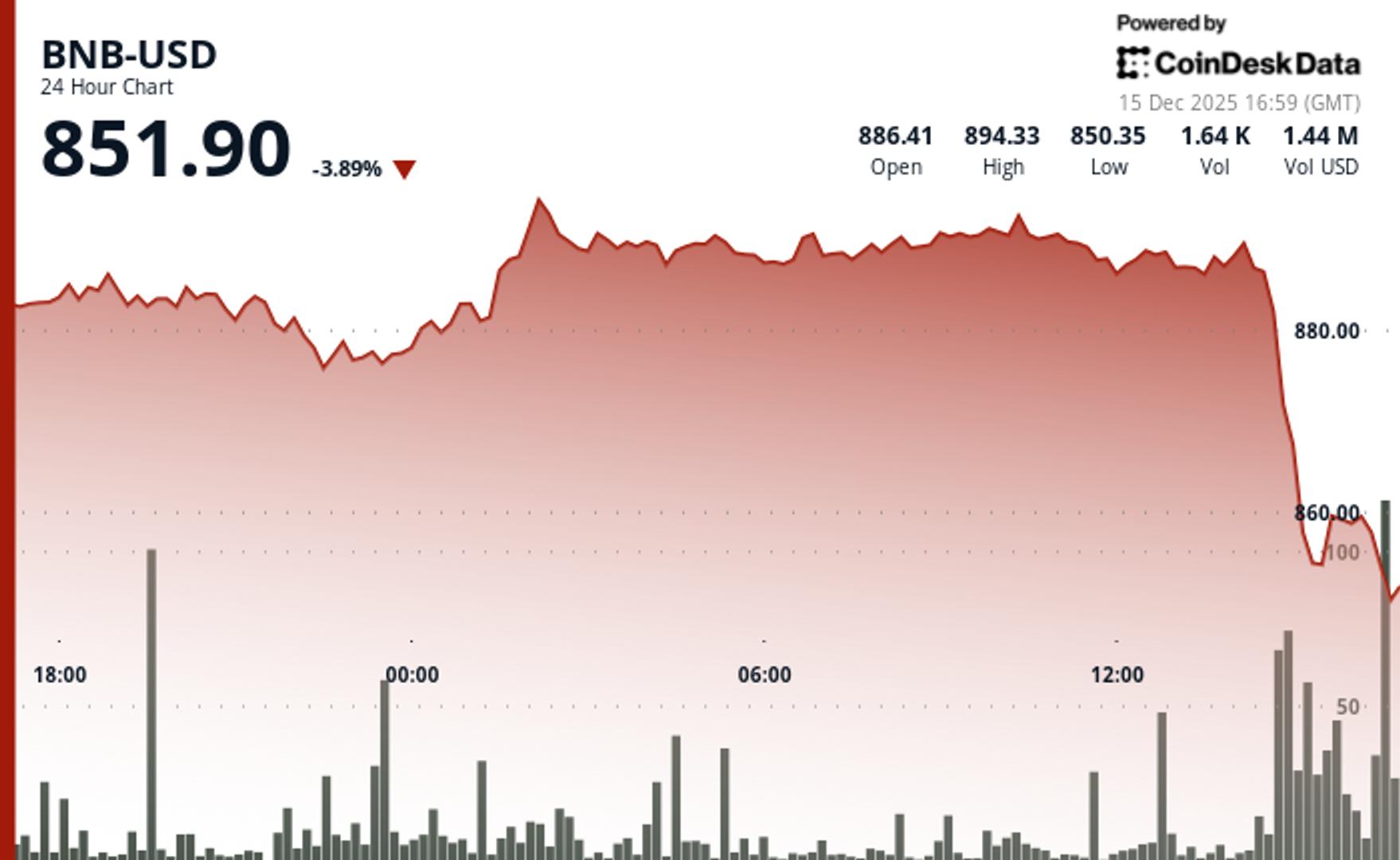
OpenAI's victory lap over its o3 model's stunning 25.2% score on FrontierMath, a challenging mathematical benchmark developed by Epoch AI, hit a snag when it turned out the company wasn't just acing the test—OpenAI helped write it, too.
“We gratefully acknowledge OpenAI for their support in creating the benchmark,” Epoch AI wrote in an updated footnote on the FrontierMath whitepaper—and this was enough to raise some red flags among enthusiasts.



















 24h Most Popular
24h Most Popular



 Utilities
Utilities