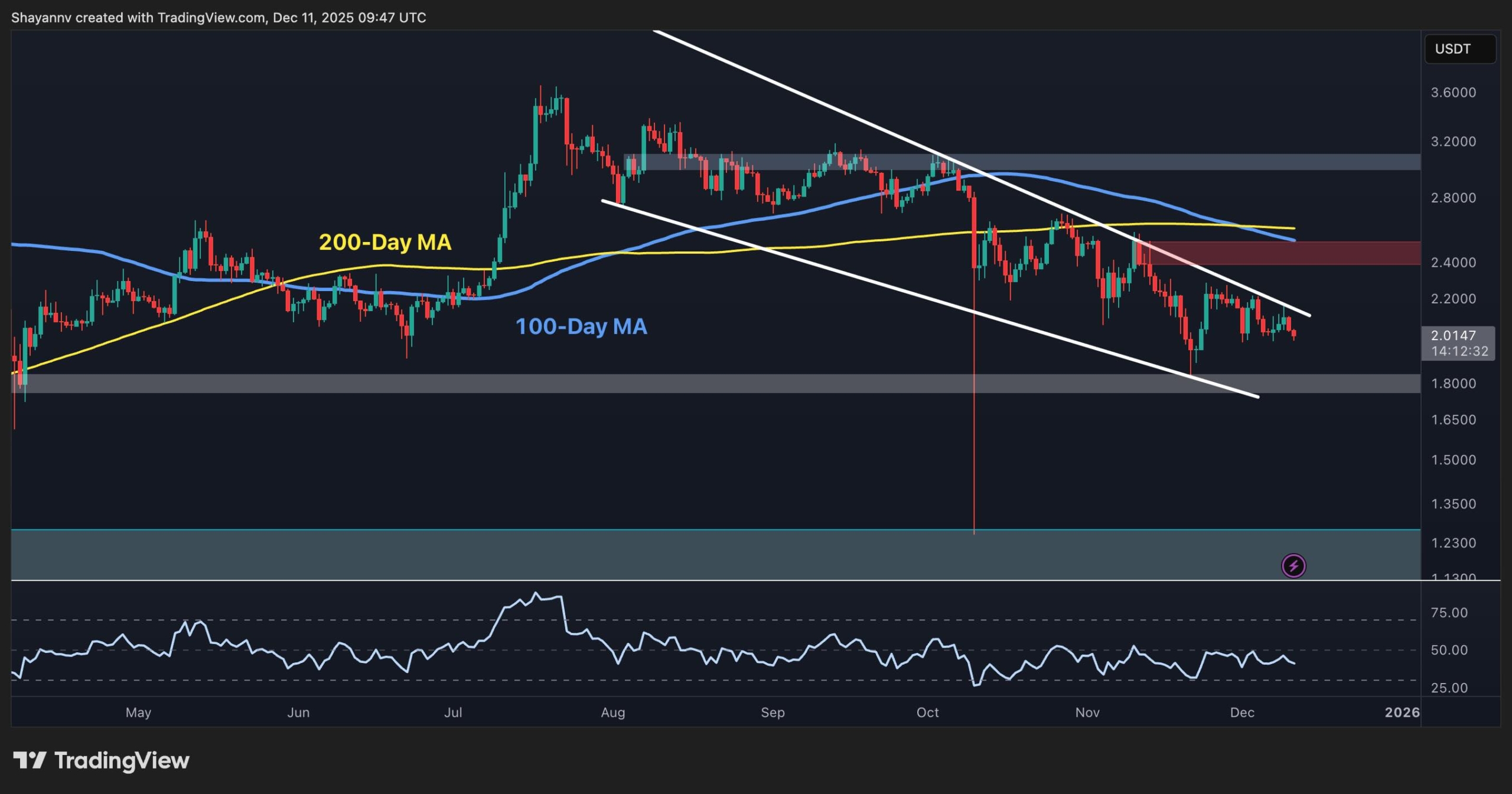
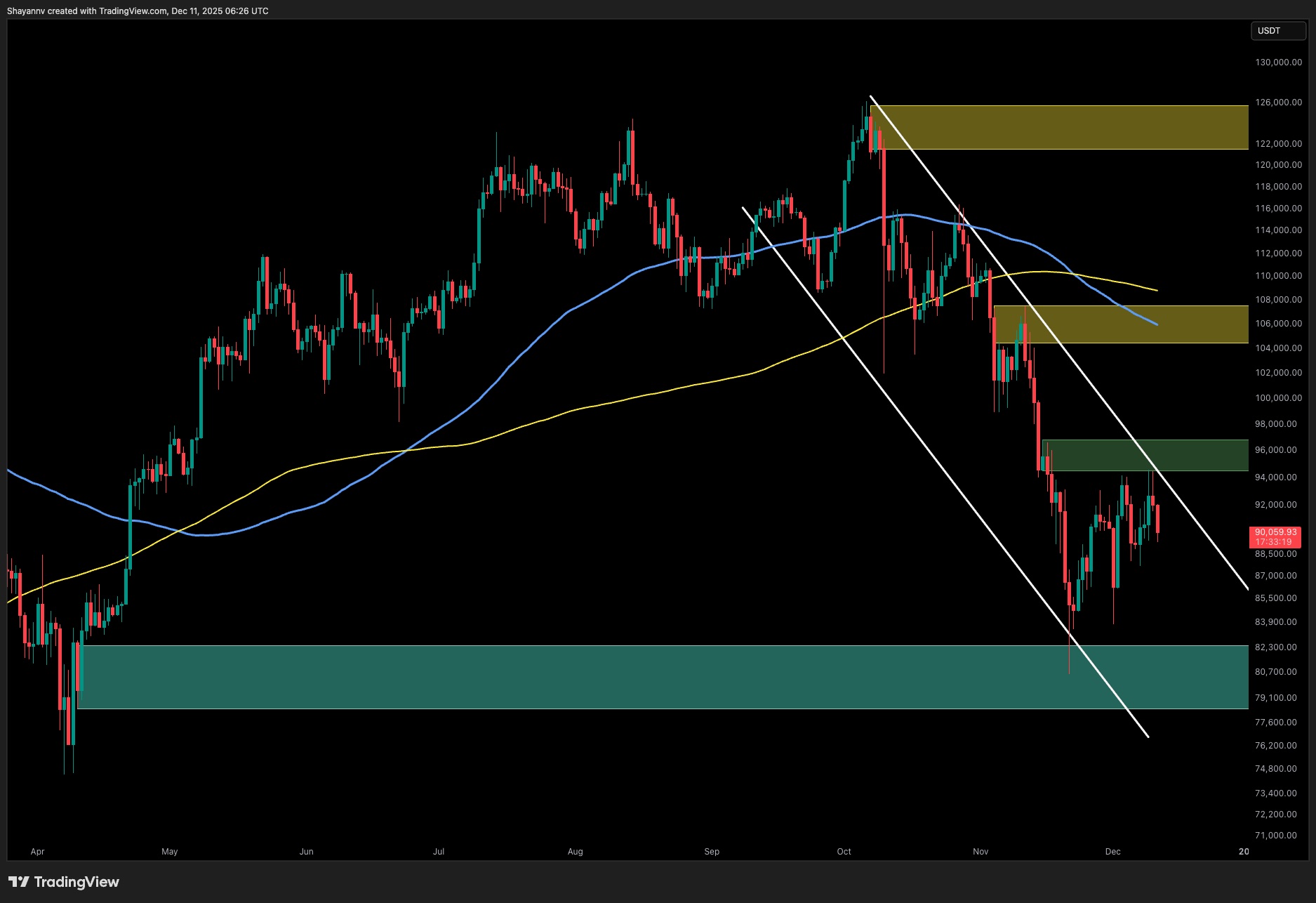
NVIDIA Dynamo introduces KV Cache offloading to address memory bottlenecks in AI inference, enhancing efficiency and reducing costs for large language models. (Read More)






 License.
License.




 24h Most Popular
24h Most Popular





 Utilities Learn
Utilities LearnBlockChain Knowledge
Cryptocurrency Knowledge
Bitcoin Knowledge
LinksXML | Ping
Follow on Linkedin
Follow on X
© BitRss - Crypto World News 2025.
All rights are reserved
BitRss World Crypto News | Market BitRss | Short Urls
Design By New Web | ScriptNet